Tördelő algoritmusunk működése és eredményei
A korpuszok előállításához egy olyan algoritmust fejlesztettünk ki, amelynek feladata, hogy felismerje egy adott újság szövegének tördelését, és összefűzze ezeket az oldalon megtalálható cikkekké. Röviden összefoglalva az algoritmust: először képelemekre (szöveg, cím, képek, vonalak, egyéb) bontjuk az adott oldalt, majd osztályozzuk ezeket a képelemeket; majd megállapítjuk, hogy az adott oldalon található képelemek hogyan állnak össze cikkeké. Ezt követően pedig digitális szöveggé alakítjuk, így felkészítve a nyelvi elemzésre.
Ahogy a fenti ábrán is látható, használtunk bizonyos, harmadik féltől származó megoldásokat is használunk a feldolgozás egy-egy lépésénél. A címek, szövegek és tördelőegyenesek (képelemek) felismerésénél a saját megoldásunkkal együtt az Abbyy Finereader tördelő algoritmusát is használtuk, a képek digitális szöveggé alakításnál pedig a Tesseract OCR megoldását vettük igénybe.
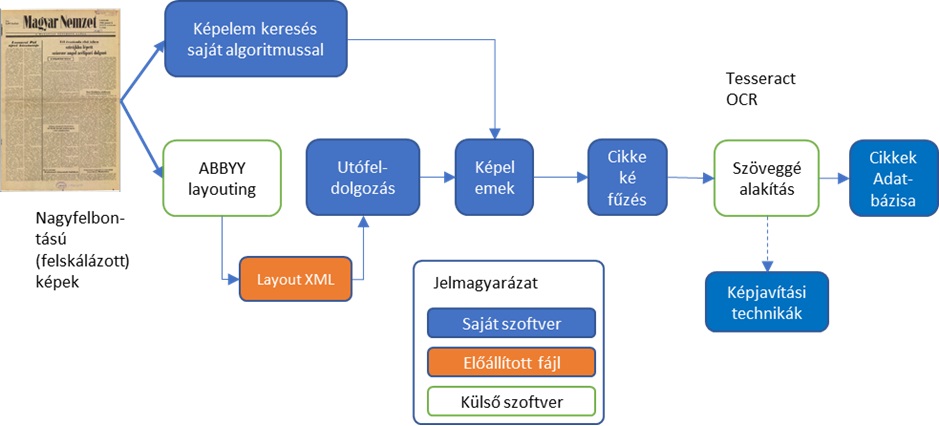
Az oldalak feldolgozásának lépései
LA feldolgozás ismertetéséhez egy a feldolgozott időszakból való, átlagos komplexitású lapot használunk. Jól látható, hogy az oldalon több cikk látható, valamint néhány kép is színesíti a tartalmat. A legelső lépés a kép szürkeárnyalatossá alakítását követően a fekete-fehér transzformáció, mely célja a kép „bináris” információvá alakítása, mely lehetővé teszi az egyszerűbb feldolgozást. Az előkészítés következő lépése pedig az oldal elemzésre nem alkalmas részének levágásal (ez az újság címét, és az előlábat jelenti).
Végül pedig az oldalról eltávolítunk minden nem szöveges tartalmat, hogy a továbbiakan ne zavarja a feldolgozást.



Elsőként a „képelemeket” azonosítjuk a lapon. Képelemnek azt a szöveges tartalmat nevezzük, ami részét képezi egy cikknek, és elemzendő tartalom. Ide tartoznak a címek, alcímek, és a cikkek szövegei.
Ezek kinyeréséhez az első lépés a kép átalakítása úgy, hogy kinyerhessük a képelemeket, illetve beazonosíthassuk azokat a határoló egyeneseket, amelyek elválasztják a cikkeket. Egyszerű képfeldolgozási módszerekkel (nyitás, zárás, összeadás) érhetjük ezt el, az alábbi ábrán látható módon. Az ilyen módon eltorzított ábrán egyszerű kontúr keresési módszereket végrehajtva majd az előálló kontúrokat összefűzve számíthatóak az egyes képelemek koordinátái és méretei.

A képelemek helyének és méretének meghatározását követően az algoritmus ezeket a képelemeket osztályozza szövegként, és címként (a határolóvonalak már az előző lépésben előálltak).
Az osztályozás számos kritérium mentén történik. Intuitív módon a szöveges tartalom, és a betűméret egyértelműen meghatározza a képelemek kategóriáit, de a kontúrkeresés tökéletlensége miatt ennél finomabb osztályozási megoldást alkalmazunk, illetve ebben a lépésben egyúttal a nem teljes képelemek (szövegek vagy címek egyes részei) egyesítésre is kerülnek, így az azonosítás és egyesítés iteratív módon többször megtörténik.
Az itt látható kép egy ilyen iteratív lépésből kiragadott állapotot mutatja. Ezen jól látszik, hogy hogyan választja szét az algoritmus a cikk címeket (zölddel), a cikkek szövegét (pirossal) és a határoló vonalakat (kékkel)

A beazonosított képelemeket ezt követően az algoritmus csoportokba rendezi a felismert határoló vonalakat felhasználva. Ebben a lépésben az alapelv az, hogy egy cikken belüli képelemek között nem lehet jelen határolóvonal. Fontos hozzátenni, hogy ez a szabály sajnos nem mindig érvényes, hiszen különböző írásos orgánumok különböző – olykor extrém logikát igénylő – tördelési megoldásokat használnak.

A csoportokba rendezett képelemek alkotják a cikkeket, amelyek megalkotása az algoritmus következő lépése. A képelemek összefűzésének logikája úgyszintén eltérhet a különböző sajtótermékek esetén. Az itt használt lapon az egyszerű cím-szöveg struktúrában azonosítjuk a cikkeket. Más esetekben azonban lehetséges a cím-szöveg-alcím-szöveg vagy egyéb logikák is.
A képelemek elhelyezkedése tekintetében a tördelés általában oszloponként balról jobbról haladva történik, az oszlopokon belül pedig a képelemek fentről lefelé követik egymást.
Ezeket a lépéseket követve egy viszonylag jó, azonban korántsem tökéletes tördelést produkál az algoritmus. Ahogy a képen is látható, számos apróbb hiba maradt a tördelés után is. A képfeliratok fennmaradtak, némely képelem mérete hibásan került azonosításra, némely esetben pedig a képelemek azonosítása nem volt helyes (például a kis betűtípussal szedett címek azonosítása). Így bár használható eredmény áll elő, a jó eredményekhez bizonyos utómunkára lehet szükség.
A tördelő algoritmus hatékonysága
A különböző feldolgozási lépések során elkövetett hibák a
végeredményként előálló korpuszban szuperponálódnak. Bár az algoritmus hatékonyan azonosíthatja a képelemeket, vagy jól kategorizálhatja őket, az ezekben a lépésekben elkövetett apróbb hibák hatása a vártnál rosszabb tördelést eredményezhet. Ebből fakadóan az egyedi lépések hatékonyságát bár fontos és érdekes mérni, a gyakorlati használhatóságot mégis jobban jellemzi a korpuszok előállításához szükséges utómunka igény.
A továbbiakban a Magyar Nemzet 1980.01.01-től 1989.12.31-ig kiadott számainak a címoldalán végzett munka adatait ismertetjük. Ebben az időszakban összesen 2456 db lap címoldalát elemeztük. Ezek jórészt hasonló struktúrával rendelkeztek, azonban bizonyos korszakonként voltak itt eltérések.
Az utófeldolgozást az algoritmus által előállított cikk struktúrán és azonosított képelemen végeztük, az utófeldolgozás maga pedig a képelemek elhelyezkedésének (x, y koordináták, szélesség, magasság) javítása, illetve a képelemekből összefűzött cikkek struktúrájának kézi javítása volt. Utóbbi állományokban minden egyes cikket egy számsor írt le, amely a cikkhez tartozó számozott képelemek számát tartalmazta az összefűzés sorrendjében.
A munkát egy egyedi, az utófeldolgozáshoz írt szoftver segítette, amely a fájlok megnyitását-mentését könnyítette meg, és vizualizálta az előálló címlapot. Ezzel együtt a szoftver mérte a feldolgozás időtartamát is, ezeket a mért időtartamokat elemezzük az alábbiakban. Ez az időtartam egy adott címlap (valamint a hozzátartozó képelem és cikk tördelés fájlok) megnyitásától, a rajta végzett változtatások befejezéséig eltelt időt jelenti.
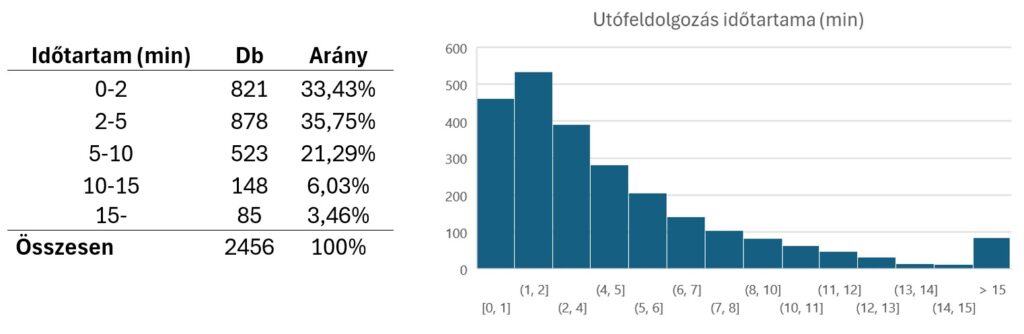
Az itt látható eloszláson látszik, hogy az oldalak több, mint 2/3-át, mint 5 perc alatt fel lehetett dolgozni. Ezekben a nyers adatokban nem vettük figyelembe, hogy egy oldal feldolgozása legrosszabb esetben 15 percet vehet igénybe, ennyi idő alatt egy oldal tördelését kézzel is el lehet végezni.
Ezeket az oldalakat 15 perces feldolgozási igénnyel figyelembe véve a mintánkban a feldolgozás átlagos időtartama 4:16 perc volt, tehát az algoritmus használatával, 15 perces teljes kézi tördelést feltételezve 3,5-szer gyorsabban állítható elő egy teljesen pontosan tördelt korpusz. Amennyiben nincs szükség teljesen pontosan betördelt korpuszra, az utófeldolgozás ennél jóval kevesebb időt vehet igénybe.