Az elemző modul használata
Az oldalon található elemző modul a TensorFlow embedding projector online vizualizációt használják. Itt számos lehetőség van az adatok 3 dimenziós vizualizációjára. Ezek elméleti hátteréről itt olvashat.
A vizualizációs modul a különböző korpuszok vizualizációja mellett lehetőséget nyújt a szavak távolságának egyedi elemzésére is. A vizualizációs oldalak használatát az alábbiakban foglaljuk össze.
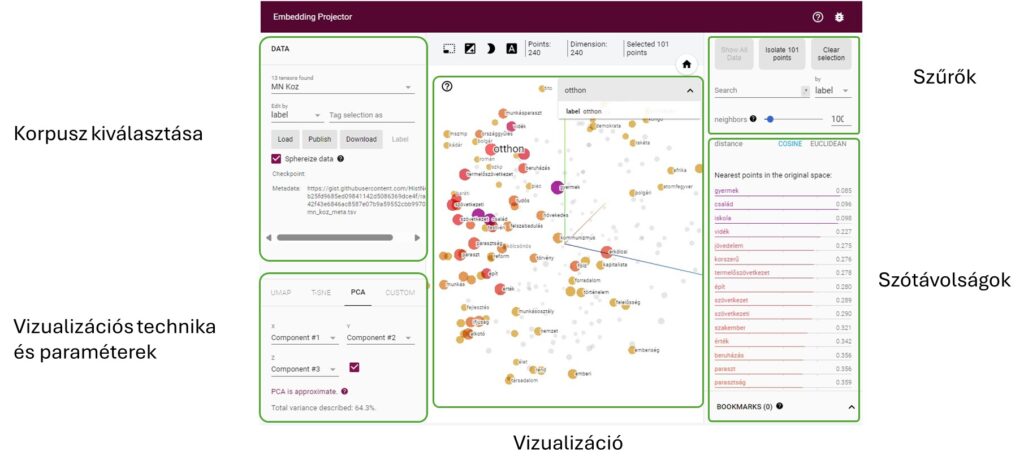
Az elemző panelen a korpusz kiválasztása, és a vizualizációhoz használt dimenzió redukciós technika beállítása után a szótávolság 2 vagy 3 dimenziós vizualizációját láthatjuk. A különböző szavakat a vizualizációban gömbök jelölik, és magát a nézetet az egér segítségével forgathatjuk (az egérmutatót a vizualizációra kell vinnünk majd a bal gombot lenyomva tartva az egér mozgatása forgatja a vizualizációt – nagyítani/kicsinyíteni az egér görgővel lehet).
Lehetőségünk van a vizualizációban lévő szavakra is szűrni (csak a cimkézett korpuszokon), illetve egy adott szóra (gömbre) kattintva a vizualizációban megláthatjuk a szó legközelebbi szomszédjaihoz tartozó távolságokat is (az eredeti vektortérben mért távolságok, tehát független a kiválasztott dimenzió redukciós módszertől).
Korpusz műveletek
A korpuszokkal kapcsolatos műveleteket az elemző panel bal felső részében található részen végezhetjük el.
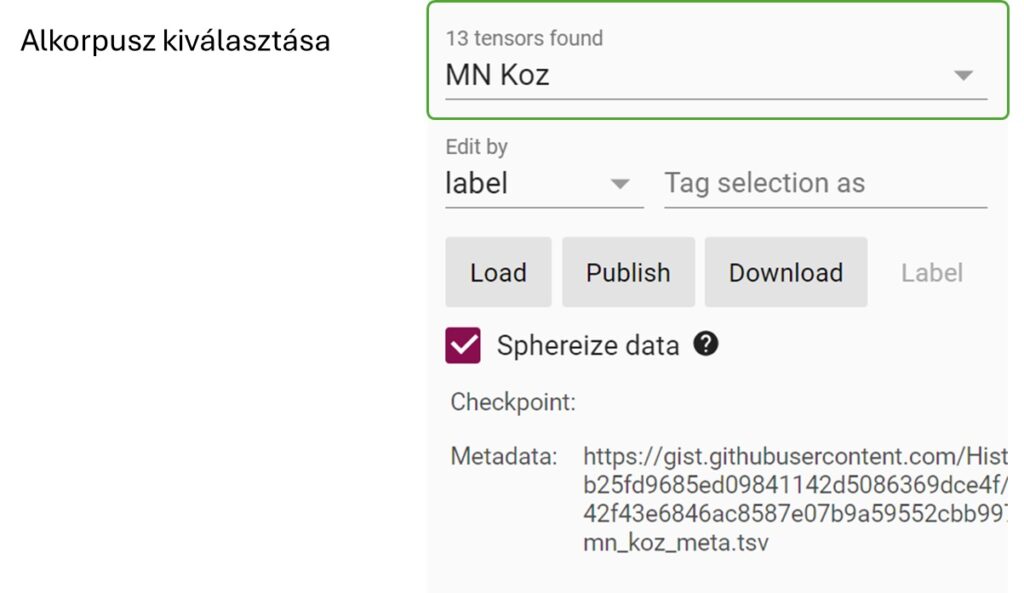
Itt a korpusz alkorpuszai közül választhatjuk ki azt, amelyiket vizualizálni szeretnénk. A korpuszokhoz tartozó elemzés oldalakon részletesen leírjuk, hogy melyik alkorpusz mit is takar.
Emellett lehetőség van itt a kiválasztott szavak megcimkézésére a „Tag selection as” szövegmező kitöltésével.
Saját adatainkat is feltölthetjük a „Load” gomb lenyomásával, melyet ugyanebben az elemző nézetben közzé is tehetünk. Végül pedig a Metadata mezőben található linken hozzáférhetünk a korpusz szótávolság mátrix metadataihoz is.
Dimenzió redukciós technikák és paramétereik
Az elemzési panelen az alábbi dimenzió redukciós módszerek érhetőek el az elemzéshez:
- UMAP: ez egy nem-lineáris manifold learning és topológia analízis alapú technika, melynek lényege, hogy a dimenzió redukcióhoz az adott pontok n darab legközelebbi szomszédját használja fel. Ezért a legfontosabb (kvázi egyetlen) paraméter is ez a mérőszám. Alapvetően 10 szomszédot szoktak ajánlani az általános felhasználásra, több szomszéd pontosabb dimenziókat eredményez, de hosszabb futásidőt von maga után. Bővebben itt olvashatunk róla.
- T-SNE: újabb nem-lineáris techika (lefordítva t-eloszlású sztochasztikus szomszéd beágyazás). Ez egy valószínűség alapú megközelítés, amely valószínűség értéket rendel a pontokhoz a távolságok függvényében, és ezt két lépcsőben teszi (először a magas dimenziókban, majd végül a redukált dimenziókban) meg. Az UMAP technika tulajdonképpen ennek egy a Riemann geometriát felhasználó változata. Ezt a technikát ez a cikk ismerteti.
- PCA: ez a standard főkomponens elemzés, azaz lineáris transzformációkkal olyan vektorteret állítunk elő az eredeti térből, amely (ortogonális) dimenziói az adatokban lévő variancia lehető legnagyobb részét magyarázzák. A vizualizációban a legerősebb (azaz legtöbb varianciát magyarázó) 2-3 főkomponens segítségével vizualizálhatjuk a korpusz szavait. Erről itt olvashatunk egy összefoglalót.
Az UMAP beállítási lehetőségei
- Dimenziók számának megadása: 2 vagy 3 dimenziós vizualizációt szeretnénk
- A számításban használt n legközelebbi szomszéd számának megadása. Ajánlott 10-15 szomszédot kiválasztani

A T-SNE beállítási lehetőségei
- Dimenzió kiválasztása: 2 vagy 3 dimenzióra redukálhatjuk a szavak vektorterét
- „Kuszaság” paraméter: ez az algoritmus által megállapított klaszterekre vonatkozik, 5-50 közé célszerű beállítani (ezen kívül furcsa klasztereket eredményezhez)
- Tanulási paraméterek: ezek az algoritmus futásidejét és az eredmények tisztaságát befolyásolhatják.
Ennél az algoritmusnál többezer iteráció szokott általában kelleni jobb redukció eléréséhez. A tanulási jellemzőkkel érdemes kísérletezni.

A PCA beállítási lehetőségei
- Adott tengelyhez tartozó főkomponens kiválasztása: a legördülő menüre kattintva válaszhatjuk ki, hogy melyik tengely melyik főkomponensnek feleljen meg. Egyúttal azt is láthatjuk, hogy az adott főkomponens mekkora %-át magyarázza a varianciának.
- 2D/3D váltás: lehetséges 2 vagy 3 főkomponens felhasználásával megjeleníteni a szavakat (azaz 2 vagy 3 dimenzióban)
- A használt főkomponensek által magyarázott variancia: ez az azokhoz a főkomponensekhez tartozó magyarázott variancia összege, amelyeket felhasználunk a megjelenítésben. Minél magasabb ez az érték, annál „beszédesebb” a vizualizáció, annál kevesebb információt veszítettünk a dimenzió redukcióval.
